
The INT in OSINT: Why the Community Stops at Collection
The INT in OSINT stands for intelligence. Most practitioners in this space know that. Fewer of them act like it.

The INT in OSINT stands for intelligence. Most practitioners in this space know that. Fewer of them act like it.
Open source intelligence has spent the better part of the last decade building out an impressive collection infrastructure. Tools, techniques, communities, certifications, conference talks, YouTube tutorials. Nearly all of it is aimed at finding information. Searching better, pivoting faster, building link charts, geolocating images, pulling records, tracing infrastructure. The collection phase of the intelligence cycle has never been better served by community resources than it is right now.
The rest of the intelligence cycle is a different story.
This is not a knock on collection. Collection is real work and it matters. But if your open source intelligence process starts with collection and ends with collection, you have not produced intelligence. You have produced research. That distinction is not semantic. It determines whether your outputs get acted on or filed, whether your clients get clarity or just more data, and whether you are developing as a practitioner or running the same loop at increasing speed.
The Intelligence Cycle Is Not Optional
The intelligence cycle runs through planning and direction, collection, processing and exploitation, analysis and production, and dissemination. Every phase feeds the next. The cycle does not begin with collection, and it definitely does not end there.
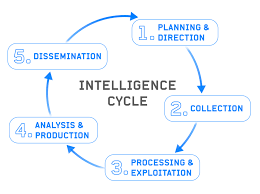
Planning and direction is where you establish what question you are actually trying to answer. It sounds obvious. It is skipped constantly. Practitioners dive into collection without a clearly defined requirement, pull everything they can find on a subject, and deliver a volume of information that the recipient now has to make sense of on their own. The pile is impressive. It is not intelligence.
Processing and exploitation is where raw collected data gets transformed into something analyzable. Translating foreign language content, extracting structured data from unstructured sources, deconflicting information from multiple collection streams. This phase is where a lot of OSINT workflows quietly collapse, because the practitioner moves directly from collection to a document without ever working through the material systematically.
Analysis and production is where the intelligence actually gets made. This is the application of structured analytical thinking to your processed collection in order to produce an assessment that answers the original requirement. It involves weighing source reliability, applying structured analytic techniques to reduce bias, calibrating confidence, accounting for gaps, and generating a judgment rather than just reporting facts. This is also the phase most OSINT practitioners have received the least formal training on.
Dissemination is where the finished product reaches the decision maker in a format they can use. Not a raw file dump. Not an email with attachments. A product structured to answer the question that was asked, presented in a way that lets the consumer understand what you assessed, how confident you are, and what they should consider doing about it.
IIRW: Introduction to Intelligence Report Writing

Knowing how to analyze is not the same as knowing how to communicate analysis. A significant amount of OSINT work breaks down at exactly that seam. The practitioner has done solid collection and soun…
Most open source intelligence workflows hit collection hard and touch the rest lightly if at all.
The Difference Between a Finding and a Product
A finding tells you something exists. An intelligence product tells you what it means, how confident you are in that meaning, what gaps remain, and what it implies going forward.
In practical terms: a finding reads as “the subject maintains three active social media profiles under different names, two of which were created within the past 60 days.” That is solid collection. A practitioner who surfaces it has done real work.
An intelligence product takes that finding somewhere. Why create two new profiles in 60 days? What do the content patterns suggest about intent or affiliation? What does the timing align with externally? What would change your assessment? What does not fit, and why? What are the competing explanations and how do you weigh them against each other?
The second version requires analytical judgment, structured reasoning, sourcing discipline, and a clear understanding of what the person asking the original question actually needs in order to act. That is a different skill set from finding the information, and the community has historically under invested in developing it.
The gap shows up wherever OSINT outputs feed real decisions. Security teams get research reports and have to determine threat relevance themselves. Corporate clients get background summaries and have to assess risk on their own. The collector has handed off the hardest part of the job to someone who was not there for the collection and does not have the full picture. That is not a failure of the individual practitioner. It is a failure of how the discipline has been developed and taught.
There is also a sourcing and accountability dimension here that does not get discussed enough. When a human analyst produces an assessment, there is a traceable chain behind it: sources consulted, reasoning applied, confidence weighed. When a practitioner delivers a collection summary without that analytical layer, there is no chain. There are findings. If one of them is wrong, or if context shifts the meaning of the data after the fact, there is nothing to review, nothing to audit, and no documented basis for the conclusions the recipient drew from the work. That is a professional exposure problem that tends to surface at the worst possible moment.
Why the Community Stays Stuck at Collection
Part of this is structural. Collection is visible and demonstrable in a way that analysis is not. Showing someone a link chart, a geolocation, a social network map, a spreadsheet of extracted records. All of it produces an immediate reaction. You can show them in a conference talk. You can build a tutorial around them. They are concrete.
Analysis is harder to package. Showing someone how you weighted competing hypotheses against each other, how you documented your confidence calibration, how you structured key judgments separate from supporting evidence. That work is less flashy and requires more baseline knowledge on the part of the audience to appreciate. The community gravitates toward what it can demonstrate, and what it can demonstrate is collection.
The training ecosystem reflects this. The certifications and courses that define the OSINT space are built almost entirely around collection methodology. Knowing which tools to use, which databases to query, which search operators to string together. Necessary skills. Not the complete skill set for producing finished intelligence.

Analytical tradecraft is its own body of knowledge. Structured analytic techniques, cognitive bias awareness, confidence standards, sourcing discipline at the assessment level rather than just the collection level. These are learnable skills that have been formalized in professional intelligence environments for decades. They do not appear in most OSINT certification tracks because those tracks were built by and for collectors. Courses like Accelerated Introduction to Intelligence (AITI) exist precisely because this layer is missing from most open source development tracks, and the parallel gap in how practitioners write and structure finished products is what something like Introduction to Intelligence Report Writing (IIRW) is designed to close. Both skills are teachable. Neither one comes from doing more collection.
What This Means for Your Practice
If you are newer to this space, here is the frame worth internalizing early: the collection phase is where you gather the material. The rest of the intelligence cycle is where you do the actual intelligence work. Getting fast and skilled at collection is valuable. Stopping there means you are delivering raw material to someone else and calling it a finished product.
AITI: Accelerated Introduction to Intelligence Course

There is a persistent gap in how most OSINT practitioners develop. Collection skills get taught early and reinforced constantly through tools, tutorials, and community practice. The analytical layer …
If you are experienced and bristling at this framing, you probably already know what the analytical layer requires. You got there somehow, through training, mentorship, or hard-won experience. The question worth asking is whether the practitioners coming up behind you are getting that same development, or whether they are learning that collection is the whole job because that is what the community modeled for them. The answer to that question is largely determined by what the community chooses to teach and what it chooses to treat as optional.
The INT in OSINT is not decorative. The discipline has intelligence in its name because intelligence is supposed to be the output. Most of the community’s energy goes into getting better at collection, which is necessary and not sufficient. The cycle does not stop there, and neither should the practice.
Clients and organizations that commission open source intelligence work are increasingly sophisticated about what they are getting. They have started to notice when they receive research summaries and have to do the analytical work themselves. Practitioners who can deliver a finished intelligence product rather than a well-organized collection dump are going to occupy a different tier of this market. The ones who cannot are going to keep wondering why their work feels undervalued.
The answer is usually not that the collection was poor. It is that the cycle was incomplete. Every phase of the intelligence process exists because leaving it out costs something: clarity, accountability, utility, trust. Collection without analysis produces data. Analysis without structured reporting produces conclusions nobody can evaluate. The full cycle produces intelligence. That is the standard the discipline names itself after, and it is worth taking seriously.