


The Internet Archive Is Being Used As A Disinformation Mule
Actors are using archive.org and exploiting the ‘Save Page Now’ feature to propagate disinformation even after their stories are removed.


As the world continues to battle the COVID-19 pandemic, some outlets are sharing samples of malware, while others are trumpeting politically biased information from both sides of the proverbial aisle, frequently perpetuating biased information as solid truth. This biased information could be disinformation, depending on the motive and subjectively, the severity. Alternatively, accidental omissions or inclusions of inaccuracies without ill-intent is misinformation. For this text, we will refer to biased media reporting from mostly-mainstream sources as politically biased information. I am focusing on disinformation.
The primary difference between the two is that disinformation is more deliberate, with motives seeking to cause more harm, hate, distrust, and doubt. In contrast, biased reporting presents an opinion or point of view as fact. Politically biased reporting can cross the line of disinformation, but this article has a specific focus outside that of mainstream and/or reputable media sources.
As we know, some nation-states and threat actors will “Never let a good crisis go to waste,” and this pandemic is no different. MalwareHunterTeam has shared a few instances of COVID-19 related malware.
While I am interested in malware, I do not possess all the technical expertise and tools to analyze them. From the same lens, I do spend a lot of time on the internet, more specifically, social media. I am connected to/friends with a lot of people outside the technology industry that are not as savvy for hoaxes and disinformation. I try to watch what they post and share and identify trends relative to disinformation and true Fake News, not just things that contradict what any specific elected official, politician, or party disagrees with and dubs as Fake News.
When COVID first gained the attention of the masses and stay at home orders were proposed, I said to myself, “There are going to be two things that come from this: Ambulance Chasers and Threat Actors.” I am surprised at the direction that this went.
Within the last week or so, I have observed an influx of stories shared from people that link to one of my favorite internet resources, especially from the lens of Open Source Intelligence (OSINT), and that is The Internet Archive (archive.org.) From Wikipedia, ‘The Internet Archive is an American digital library with the stated mission of “universal access to all knowledge.”’
I have observed links to direct disinformation campaigns being shared on social media with links to the Internet Archive. At first, I scoffed it off then began to see a pattern. Below is the analysis.
Sample 1
Starting with the first sample I saw, let’s take a look. Here is the link being shared:
Covid-19 had us all fooled, but now we might have finally found its secret.
In the last 3–5 days, a mountain of anecdotal evidence has come out of NYC, Italy, Spain, etc. about COVID-19 and…web.archive.org.
Here is what we see by clicking the link:

Disclaimer: I am not a doctor or a trained medical, pharmaceutical, or chemistry professional. This analysis is from the perspective of language and the methods by which this article is shared on the internet.
In evaluating this article, there is no single link to anything, much less a reputable source or medical journal. A user on YCombinator pointed out that the author responded to criticism about failing to link any material with “I’m not an academic so f**k all that citation waste of time”. The language of the section is written to the layperson initially but then starts to pick up in the use of medical terminology. As we scroll down in the subject sample, we see this:

The language used here is not that of someone in the medical or chemistry fields. The statement that Hydroxychloroquine is an advanced descendent of regular old Chloroquine is false. The difference is the chemical makeup. Hydroxychloroquine has the same composition as Chloroquine with an additional Oxygen atom (C18H26ClN3O for Hydroxycholorquine versus C18H26CIN3). The difference between the two is in the manufacturing of the drugs, not something that occurs organically in nature.
Why is this relevant when discussing disinformation?
Not only is this ‘article’ disinformation, but Medium also took it down and suspended the user (as evidenced below). Note: To test this, remove the archive.org URL up to the https:// that starts the Medium URL.

So, I decided to see what credentials the user has to discuss medicine and COVID. Using OSINT, I was able to find their social media accounts, which I am not going to share in preserving their privacy. This is a censored screenshot of their Twitter:

When I attempted a search on Facebook for the author by name, instead of seeing an account, I was confronted with numerous posts debunking his research, similar to this article. I am embedding one post that is from someone claiming to be a Medical Doctor (MD) with a Master of Science (MSci). A search for her on LinkedIn confirms the information she presents about herself on the Facebook page. I was also able to find her profile on one of the employers that the LinkedIn profile claims to work for, so I rate her as credible.
Here is a picture of the screen I was presented with while searching for the author:

Sample 1 Conclusion:
This piece is written to further a political narrative. The author has no credibility and is deliberately trying to spread disinformation. I am not sure to what end, but some of the posts on Facebook do mention that this is making its rounds on 4Chan. A few Google dorks across 4chan yielded a high number of results of the link to this sample, but no other COVID-19 specific posts, as verified from implementing a filter that excluded results for the sample in question.
Whether the author is the source of spreading the archive.org link or not is undetermined. Using LinkedIn, I was able to identify the author, but I was unable to find any evidence that they are the source of sharing the archive.org link. I was able to ascertain that the author is active in supporting political candidates that may subscribe to the narrative of this sample.
Sample 2
Sample 2 is a lot more complicated. Warning: There is a rabbit hole to fall with this one. From my estimation, this is more likely to come from a state-sponsored actor that Sample 1. There are a lot of moving parts to unpack. Let’s start the same way we did with Sample 1. Here is the link being shared:
21 million Chinese died of coronavirus — US intelligence officials intercept data — Washington Live
A new data intercepted by the United States reveals that 21 million people died in China from December 2019 to March…web.archive.org
Here is what we see by clicking the link:

The portions that are highlighted (less the number of captures in the top left corner) were searched for on the internet in an attempt to find a reputable news source that reports any semblance of this; however, that was unsuccessful. A site that attempts to look like a TV station was identified and will be discussed below. Attempts to verify the information contained in this article were futile, less some of the fundamental facts, such as the parts about facial recognition and the decline in phone users. All sites that had similar statements to this one and none were reputable. I came across another site, similar to the one mentioned above, which will also be discussed below.
When navigating to the live site, I saw this:

First of all, notice the WordPress logo on the tab in the absolute top left corner. Any reputable news site would have their logo instead of WordPress. I would like to say that many large news outlets have their content management system provided by their parent company. Still, it has been almost a year since I wrote for Forbes, and they were on WordPress until a few weeks before I stopped writing for them, although it was branded with Forbes logos.
Next, notice the writing in Vietnamese. According to Google Translate, this is translated into:
Read Vietnamese
Breaking news: The family of three Hanoians died before testing positive for coronavirus
This is not included in the original piece, which indicates that this is being used as a staging ground or template for other similar stories. There is only one author, and all stories are COVID-19 related. Another peculiar thing about this site is that sometimes a full name is in the URL; other times, it is the story ID. This is usually due to a misconfigured CMS like Wordpress.
Let’s take a quick look at WHOIS data to see if that tells us anything.

We see the domain is 41 days old, which is a bit suspect. The WHOIS record indicates that the registrant is using Domain Privacy, but is in the US and that the registrar is Wild West Domains, a subsidiary of GoDaddy, according to their about page.

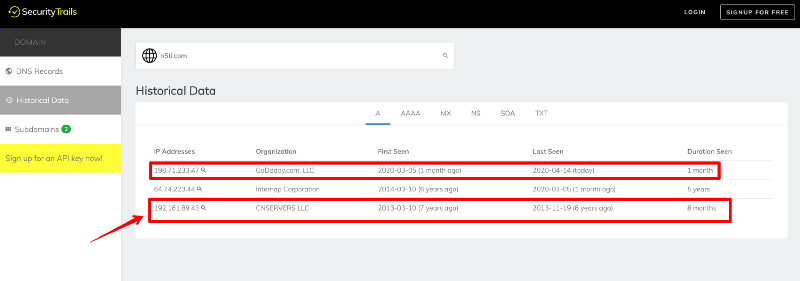
Getting a little more information from SecurityTrails, we see the domain history for the domain. The current hosting for the domain was opened on March 5, 2020, which corroborates with what we saw from DomainTools. We also see two other IP Addresses that it occupied. The one without a box around it hosts about four other sites that do not load. The one with an arrow pointing at it hosts a Chinese porn site. While the porn site sets off some alarms, it was only hosted there for eight months in 2013 before popping up on the next one in March 2014 for six years.
Pivoting to social media to dig further, I journeyed on the ride of my life. Doing a little bit of research using the verbiage of the story is where this flow gets messy. First, I attempted to search for the author by name, which yielded nothing, which is very suspicious as most reputable journalists have social media platforms and their work email addresses shared for people to send leads to.
Next, I was attempting to fact check the main points by searching in Google and on Facebook. Because aspects of the story came from other sources, this was not very fruitful in determining the validity of the claims. It appears as if every claim is mostly true, but not in the context provided in the story, thus qualifying as disinformation.
Facebook, on the other hand, brought some serious stuff out. I searched for the author’s name there and found a few accounts, but could not pinpoint whether any of them were the person in question. I did, however, note several accounts with near-identical verbiage pushing the ideas of the story through copying and pasting the story as Facebook statuses. Five were public. The picture below shows them.

I decided to see what I could gather from these accounts to see if they were bots or just people who believed the story. One was for ex-pats of one country residing in another. The tone of that post was to try to spread the information, but the people in the comment section were not having it. One of the other accounts lists their phone number in the open. They breed and sell dogs. This same account was consistently sharing conspiracy theory-type stories about COVID-19 and Hydroxychloroquine. A lot of the sources that this user was sharing stories from have been rated as conspiracy theories on MediaBiasFactCheck.com.
I next searched Facebook for the archive.org link. One of these accounts was a little more aggressive than the previous one. They were sharing both the text as a post and the archive.org link to the story. They also shared a Google drive link for a folder with the title of VIRAL, which displayed this (when accessed via a safe system):
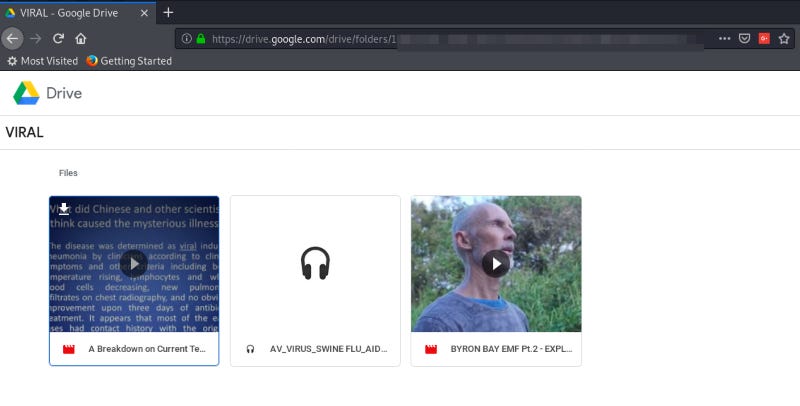
Everything else this user shared was from or about a technology firm that “can promote the regeneration of the fabric that has been destroyed by the virus, therefore strengthening immunity is not enough in many cases,” which screams hoax or snake oil.
The next merely shared the link and had nothing else of immediate interest. The next account appeared to be aggressively sharing COVID-19 related articles but in Tamil. I was unable to translate many of the posts since I was trying to avoid downloading all the memes and pictures and run them through an optical character recognition (OCR) reader and then a translator.
Here is precisely where it gets more volatile. One of the other accounts posting the link also posted in Tamil but also mentioned Pakistan frequently. This is odd because one of the accounts that also shared the link claims to be Dr. Gholam Mujaba, a prominent figure in Pakistan with some alleged ties to the US. Due to the Wikipedia page being laden with missing links and accolades such as Co-leader of the top Clash of Clans clan as of 3/26/20, it seems all but impossible to identify if this is a real account. It is not verified, and a LinkedIn with the same name has a lot of the same information, but missing logic and citing things out of place.
Regarding the picture below, the section in the top red box is a common fake copyright notice that makes its way across Facebook from time to time. The terms of service of Facebook negates 100% all of this statement. Under Copy RIGHTS [sic], we see mention of the phrase This FB page, which is rather unprofessional, followed by a Gmail address with Affiliation with the Republican National Convention, USA, despite listing political views as Liberal. I am not trying to split hairs, but the US Republican party tends to refer to themselves as the GOP, rather than the RNC. This seems to be created by someone seeking to cause political turmoil without knowledge of American politics.

Here is the empty link section for Wikipedia. In reviewing the Wikipedia page’s edits as far back as 2008, his page seems to attract vandals and false editors. Many of the accolades and accomplishments that would’ve been known at the times of the edits were added much later. For example, mentions of his Masters in Pharmacology and his Ph.D. were added in May 2018 by an IP Address that belongs to RCN, which is an ISP in the area between Washington DC and Philadelphia as well as New York, Boston, and Chicago, per their website. To be clear, I am not saying that there is not a person by the name of Dr. Gholam Mujtaba with these credentials and accolades. I am saying that I am not 100% convinced that the accounts purporting to belong to him are authentic.

While this account is questionable, one linked to him seems to have more of an agenda in what they are publishing. Pakistan Policy Institute, USA, is an organization that allegedly seeks to help bring US and Pakistan relations to a more equitable position for both countries. Some of the verbiage listed in the About section of the Pakistan Policy Institute, USA Facebook page in conjunction with the link to a registered website with nothing to load, makes me skeptical.

The part in this about the US being Pro-India is awkward. Understanding that India and Pakistan have a tumultuous relationship at best still sets off alarms as to why this person who is affiliated with this organization would be sharing COVID-19 propaganda. Diving a little further into the posts for this page, we see a couple of alarming samples not relevant to COVID.

Admittedly, some of this does not make sense to me. The mention of Germany and the female to bow down on the threshold of non-Allah confuse me. I know this is a rough translation, but I lack the context to know what this has to do with COVID-19. I am unsure as to why New Jersey is mentioned. The final highlighted section seems to be counterproductive to what the About for this group says. This seems very Anti-India, which could be seen as a provocation, which fuels suspicion of a state actor maintaining these pages. The remainder of the posts reviewed were all about COVID-19, and some mentioned his son, who is a doctor in a New York hospital.
Traveling back to searching for phrases in Sample 2 to attempt to verify any validity to the statements led me to another source of disinformation. This site attempts to look like a real news station.

While this looks like a news station, something is noticeably missing: the other journalists. Brandon G. Jones wrote every single article. Clicking his name to see his profile and how to follow him on social media leads us to this:

The URL says abc14news.com/author/bob instead of mentioning Brandon. I put a box where one would expect links to his Twitter, Facebook, and Email address. Attempting to move to the author’s directory to see if any other authors are listed redirects us to an article that starts with the word author. I tried a reverse image search for his picture, but nothing came up. A search for only produced ABC14news materials.
Looking at the WHOIS and hosting history, we see that it is registered through GoDaddy with Domain privacy enabled. A pattern in play since September 2019 shows that the site moves hosting providers about every month or two.

As of the time of writing this, abc14news.com seems to be the only site on the IP address. Previous IP addresses have hosted a wide variety of sites in terms of content and credibility.

It appears as if the modus operandi for ABC14News is to regurgitate Fox News stories but to replace the words with synonyms so as not overtly to plagiarize the work. Take a look at the two links below. View them side by side, and you will see what I mean.
Sanders hit for lackluster record of getting bills passed despite decades in Congress | ABC 14 News
Sen. Bernie Sanders is using a lot more hits from critics who problem regardless of whether the White Dwelling hopeful…abc14news.com.
Sanders hit for lackluster record of getting bills passed despite decades in Congress
Sen. Bernie Sanders is taking more hits from critics who question whether the White House hopeful achieved anything of…www.foxnews.com
Below is an analysis of ABC14News from NewsGuard:
Sample 2 Conclusion:
This piece is pure disinformation and shared via archive.org for malice. While attributing the author was not possible, it seems that it may be motivated by international relations or politics — possibly perpetrated by a state-sponsored actor. Because of all the moving parts with this, it became complex very quickly. There are other rabbit holes to pursue this, but I thought this was a good stopping point for now.
How did this happen?
So how did these articles come to light and use Archive.org as a mule to spread disinformation? Simple, they exploited a single feature in the Wayback Machine — The Save Page Nowˆfeature. This can be triggered and used to create an alternative link to the article so that if in the case of Sample 1, it gets taken down, it is still shareable.



It appears as something within the Wikipedia Eventstream triggered indexing and saving of sample 2.

Final Conclusion
No good deed goes unpunished. Archive.org was stood up to memorialize parts of the internet for research and leisure purposes, and like anything else, someone has found a way to weaponize it. Be cautious of the links you share and those you see other people sharing. Feel free to use this article to help explain what is off about the pieces and why it is disinformation meant to harm people. As to who those people are, the jury is still out on that one.